

일반적으로 인터넷을 이용하면서 웹에 있는 데이터를 가공하거나 사용해야 하는 경우가 빈번 합니다. 특히 사이트에서 어떤 가격에 대한 데이터를 받아 엑셀로 저장하여 정리하여야 한다던가, 여러 페이지들을 돌면서 최저가 아이템을 구입하길 원하는가 등 여러 니즈들이 있을 수 있는데, 이때 주로 requests, bs4, selenium4을 이용하여 프로그램을 개발하여 해결합니다.
이번에는 파이썬을 통해 해당 니즈들을 해결하기 위해 동적인 웹 페이지에 대한 데이터를 크롤링하는 방법에 대해서 알아보고자 합니다.
- 웹 데이터 크롤링이란 프로그램이 웹사이트를 정기적으로 돌면서 정보를 추출하는 것을 의미 합니다.
동적 페이지 vs 정적 페이지 그리고 데이터 수집
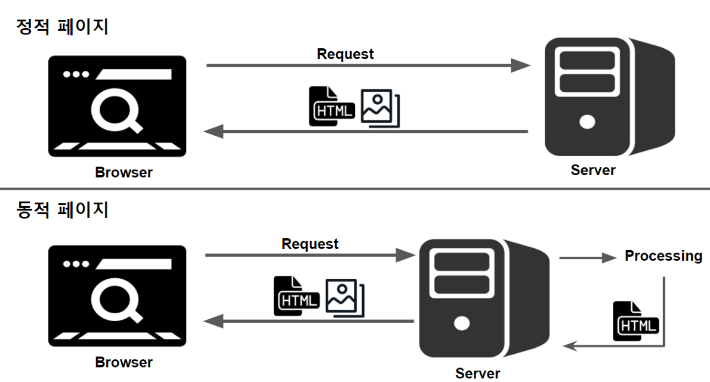
정적, 동적 페이지라는 말이 생소하게 들릴 수 있는데 간단하게 이야기하자면 저장되어 있는 파일을 그대로 보는 웹 페이즈를 정적 페이지, 다른 변수들에 의해 변경되어 보이는 페이지를 동적 페이지라고 합니다. 동적의 페이지는 사용자의 상황, 시간, 요청에 따라 달라지기 때문에 일반적인 방법으로 데이터를 크롤링하기는 어렵습니다.
따라서 저는 데이터 크롤링을 하기 위해 다음과 같은 순서를 거치는데 순서는 아래와 같습니다.
- requests와 bs4을 통해 내가 원하는 데이터를 받을 수 있는지 체크하여 정적 페이지인지 동적 페이지인지 체크 합니다.
- 만약 내가 원하는 데이터를 받을 수 없다 판단 시, Selenium을 통해 데이터 크롤링을 진행합니다.
정적 페이지에서 데이터 크롤링
정적 페이지에서 데이터를 크롤링하기 위해서 requests, bs4 라이브러리를 설치 합니다.
- Terminal
pip install requests && pip install bs4
requests의 역할은 해당 페이지에 요청을 보내 페이지에 대한 각종 데이터에 대한 응답을 받는 역할이고 bs4는 그 데이터를 가공하여 우리가 사용하기 쉽게 만드는 역할을 합니다.
이번에는 requests을 통해 디시인사이트라는 사이트에 요청을 보내 응답을 받은 다음 받은 응답 데이터를 bs4을 이용해 원하는 데이터를 가져오는 실습을 진행해 보도록 하겠습니다.
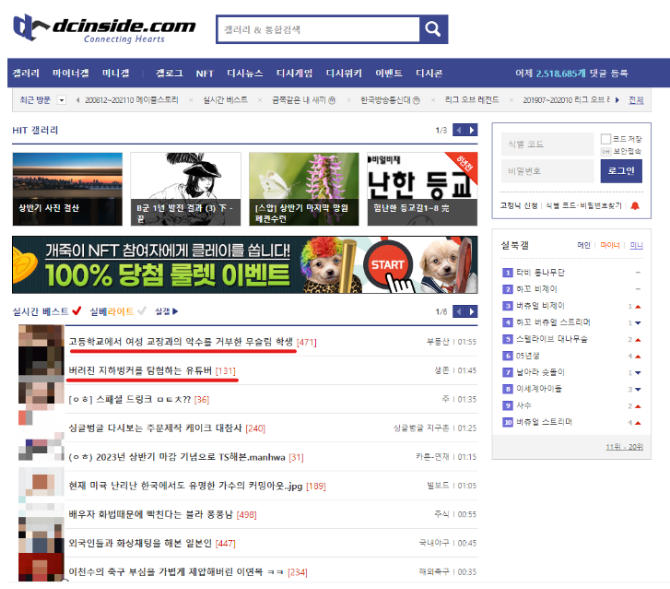
이 중에서 각 제목에 대한 데이터를 가져오고 싶다고 가정해보겠습니다. 그러고 나서 어떻게 데이터를 가져올 건지에 대해서 설계를 하면 되는데 설계 방법은 다음과 같습니다.
- 제목이 어떤 큰 틀에 대해서 묶여 있는 형태 임으로 큰 틀에 대한 데이터를 먼저 가져 옵니다.
- 가져온 큰 틀에 대한 데이터에 대하여 제목만을 추출하여 화면에 출력 합니다.
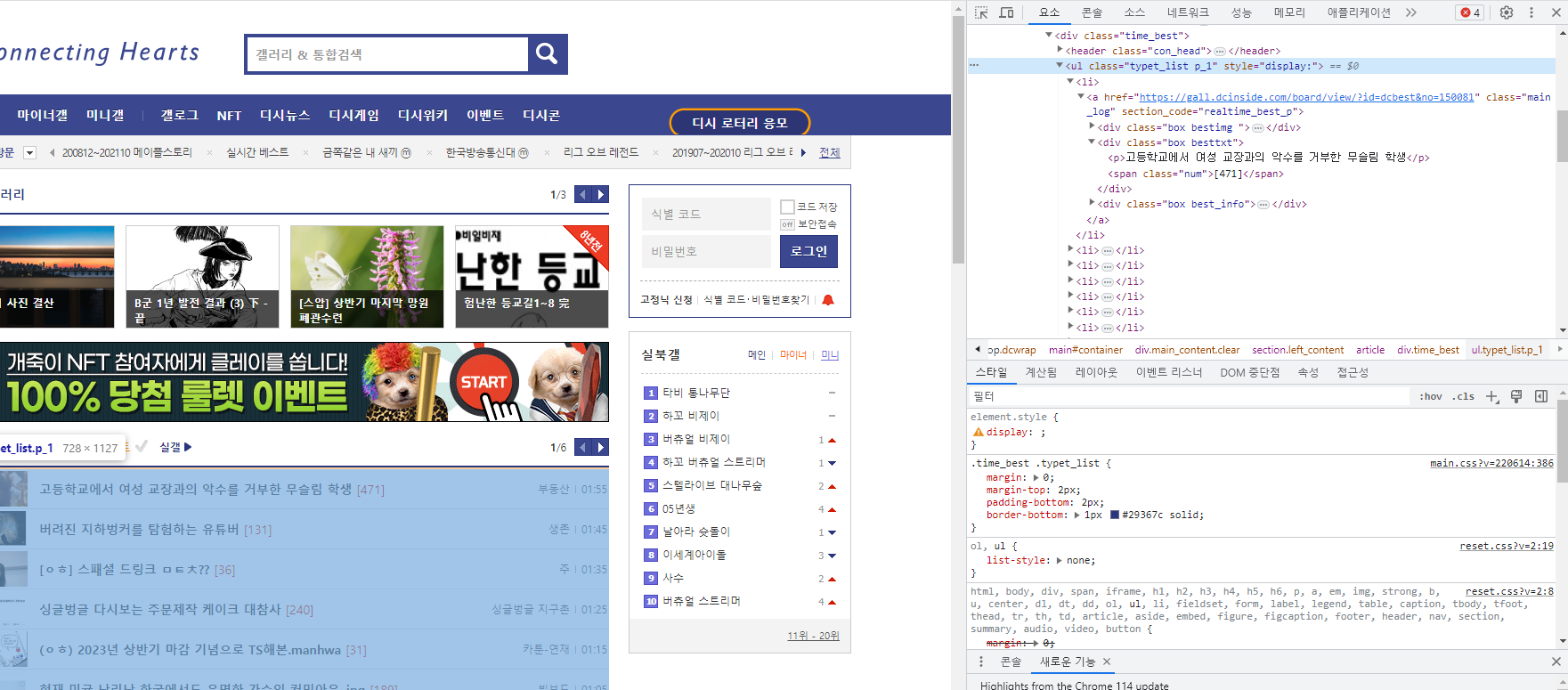
F12을 누르게 되면 각 페이지에 대한 요소들을 확인할 수 있는 창이 뜨는데요, 이를 통해서 어떤 태그에 어떤 데이터가 담겨있는지 확인할 수 있는데, 현재 각 제목은 <ul class"typet_list p_1" style="display:"> 태그에 포함되어 있음을 확인할 수 있습니다.
즉 <ul class "type_list p_1" style="display">에 대한 데이터를 먼저 가져온 뒤, 나중에 아래에 있는 태그에 대해서 가져오면 될 듯 합니다. 아래는 해당 태그에 대한 정보를 가져오는 방법입니다.
- main.py
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.dcinside.com/")
html = response.text
soup = BeautifulSoup(html, "html.parser")
cases = soup.select("#container > div > section.left_content > article:nth-child(2) > \
div.time_best > ul.typet_list.p_1")
해당 코드는 BeatuifulSoup(html, "html.parser")는 응답받은 데이터를 html 형식으로 찾기 쉽게 가공했다는 의미이며 아래 코드는 그 가공한 soup 데이터를 통해 우리가 원하는 데이터를 찾아내는 코드 입니다.
우리는 soup에서 html 파일의 각종 태그들과 css을 이용하여 데이터를 가져오는 방식으로 크롤링을 진행 합니다. 일반적으로 가져오는 방법은 find, select 2가지가 있는데 find는 태그를 이용하여 데이터를 찾아 가져올 때 사용하며 select는 css 이용하여 데이터를 찾아 가져올 때 사용합니다.
find을 이용하는 방법, select을 이용하는 방법은 취향에 따라 사용해도 되지만 find을 이용하는 방법이 생각보다 까다롭기 때문에, 대부분의 블로그나 문서에서는 select을 이용하여 처리하는 방식을 더 선호하거나 추천하기도 합니다.
따라서 이번에 데이터를 크롤링할 때는 select을 이용하여 데이터를 크롤링을 해보겠습니다.
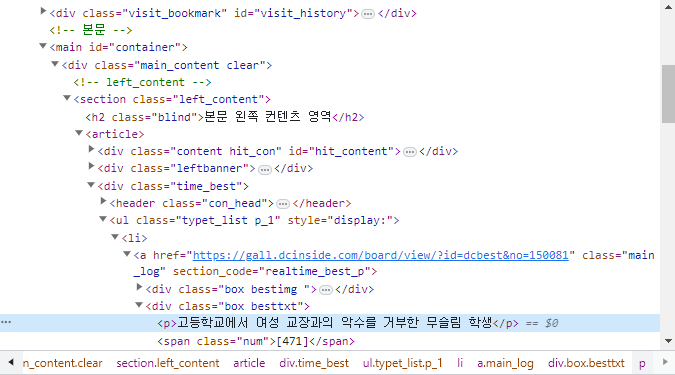
현재 아래 코드는 select문을 이용하여 큰 틀에 대한 데이터를 가져와서 cases라는 변수에 데이터를 담았습니다. 저희가 필요한 건 제목에 대한 데이터를 가져오는 것인데 현재 페이지를 살펴보면 제목은 p 태그로 이루어져 있음을 확인할 수 있습니다.
따라서 select문을 통해 p 태그에 대한 데이터를 가져와서 화면에 출력해보겠습니다.
🖥️ main.py
import requests
from bs4 import BeautifulSoup
response = requests.get("https://www.dcinside.com/")
html = response.text
soup = BeautifulSoup(html, "html.parser")
cases = soup.select("#container > div > section.left_content > \
article:nth-child(2) > div.time_best > ul.typet_list.p_1")
answers = ""
for case in cases:
answers = case.select("p")
for answer in answers:
print(answer)
# 출력
# <p>고등학교에서 여성 교장과의 악수를 거부한 무슬림 학생</p>
# <p>버려진 지하벙커를 탐험하는 유튜버</p>
# <p>[ㅇㅎ] 스패셜 드링크 ㅁㅌㅊ??</p>
# <p>싱글벙글 다시보는 주문제작 케이크 대참사</p> ...
정상적으로 제목이 출력되는 것을 확인할 수 있습니다.
이렇게 정적 페이지에 대한 크롤링을 진행해 보았습니다. BeatifulSoup의 함수인 find, select에 대한 부분은 아래 블로그에서 정리를 잘해놨으니 혹시 사용에 어려움을 느끼신다면 해당 블로그에서 정보를 얻어보심을 추천드립니다.
티스토리 : https://desarraigado.tistory.com/14
BeautifulSoup 모듈 find와 select의 차이점 - 복잡한 웹을 간단하게
BeautifulSoup은 HTML 문서를 예쁘게 정돈된 파스트리로 변환하여 내놓는 파이썬 라이브러리다. 이 잘 정돈된 데이터 구조는 Beautiful Soup 객체로서 여러 tag 객체로 이루어져 있다. 영어, 한국어와 같은
desarraigado.tistory.com
동적 페이지에서 데이터 크롤링
이번에는 동적인 페이지에 대한 데이터를 크롤링하는 방법에 대해 알아보도록 합니다. 동적인 데이터를 크롤링하기 위해서는 selenium 라이브러리를 설치하여야 합니다.
pip install selenium
그런 다음 아래 코드를 복사해 붙여 넣습니다. 해당 코드는 selenium의 여러 옵션을 통해 크롬을 열어 직접적으로 데이터를 탐색하여 가져오는 방식이다. drive.get(원하는 url)을 통해 사이트에 접속한 뒤 원하는 데이터를 가져오는 형태로 진행합니다.
- main.py
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
options = webdriver.ChromeOptions()
# 크롬을 백그라운드로 실행시키고 싶다면 해당 옵션 추가
# options.add_argument("headless")
# 모바일로 사이트에 접속하고 싶다면 해당 옵션 추가
# mobile_emulation = { "deviceName": "iPhone 12 Pro" }
# options.add_experimental_option("mobileEmulation", mobile_emulation)
# options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36")
options.add_experimental_option('excludeSwitches', ['enable-logging'])
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option("useAutomationExtension", False)
options.add_experimental_option("detach", True)
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
해당 부분 실습은 위키독스의 "파이썬을 활용한 업무 자동화"라는 책에서 설명이 엄청 잘 돼 있기 때문에 이를 통해 학습하는 것을 추천드립니다. selenium 라이브러리에서 제공하는 옵션이나 관련 이벤트를 처리하는 부분은 모두를 외울 수 없기 때문에 해당 위키독스 사이트를 참고한다면 쉽게 코드를 작성할 수 있습니다.
위키독스 : https://www.wikidocs.net/177133
01. selenium 4
[TOC] ## 셀레니움 설치 ```{.python} pip install selenium # pip install selenium-wire # 특정 버전 설치 pip insta…
www.wikidocs.net
robots.txt
robots.txt는 웹 사이트에서 크롤링하며 정보를 수집하는 크롤러가 액세스 하거나 정보를 수집해도 되는 페이지가 무엇인지, 안 되는 페이지가 무엇인지 알려주는 역할을 하는. txt 파일입니다. robots.txt 파일은 검색엔진 크롤러가 웹사이트에 접속하여 정보 수집을 하며 보내는 요청(request)으로 인해 사이트 과부하되는 것을 방지하기 위해 사용됩니다.
해당 robots.txt 파일을 읽기 위해선 웹 사이트 메인 페이지에서 /robots.txt에 접속하여 문서를 읽을 수 있는데요, 예를 들어 naver에서 제공하는 robots.txt 문서를 읽어 보도록 하겠습니다.
🖥️ naver robots.txt
User-agent: *
Disallow: /
Allow : /$
네이버에서 제공하는 robots.txt을 보면 User-agent 와 Disallow, Allow를 볼 수 있는데 이는 각각 다음과 같은 역활을 합니다.
- User-agent : robots.txt에서 지정하는 크롤러
- Allow : 크롤링 허용할 경로
- Disallow: 크롤링 제한할 경로
robots.txt는 웹 사이트에 대해서 웹 크롤러 같은 로봇들의 접근을 제어하기 위한 하나의 규약 즉 권고안이라 꼭 지킬 의무는 없지만 왠만하면 꼭 지켜주는 것을 권하고 있는 편입니다.
'Programing Language > Python' 카테고리의 다른 글
| unittest을 통해 테스트 코드 작성하기 (0) | 2023.12.12 |
|---|---|
| 문자열 모듈 String을 이용해서 문자열 모음 가져오기 (0) | 2023.11.24 |
| 코드 포맷터의 의미와 파이참에서 Black으로 코드 스타일 자동화 하기 (2) | 2023.11.23 |
| pyautogui을 이용하여 자동화 기능 만들기 (1) | 2023.10.28 |
| 추상 클래스와 덕 타이핑 (0) | 2023.09.06 |